前言
本文记录了笔者近一年以来在各类法律实习工作中,尤其是在重复性、机械化劳动领域积攒的一些经验和方法,并就文中给出的三个示例浅谈统筹方法的重要性。三个示例分别为:①模板化的法律文书准备;②同类案件证据材料准备;③将非常模糊的图片转化成可编辑的word文档。
正文
统筹方法,是一种安排工作进程的数学方法。这几个字眼早在初中时期的语文课堂就已出现过,其出自华罗庚的同名说明文《统筹方法》,作者在文中抛出了“泡茶”这个例子,讨论这一事项工作步骤(工序)排列的重要性。
比如,想泡壶茶喝。当时的情况是:开水没有;水壶要洗,茶壶,茶杯要洗;火已生了,茶叶也有了。怎么办?
办法甲:洗好水壶,灌上凉水,放在火上;在等待水开的时间里,洗茶壶、洗茶杯、拿茶叶;等水开了,泡茶喝。
办法乙:先做好一些准备工作,洗水壶,洗茶壶茶杯,拿茶叶;一切就绪,灌水烧水;坐待水开了泡茶喝。
办法丙:洗净水壶,灌上凉水,放在火上,坐待水开;水开了之后,急急忙忙找茶叶,洗茶壶茶杯,泡茶喝。
哪一种办法省时间?我们能一眼看出第一种办法好,后两种办法都窝了工。
[百度百科-统筹方法 (数学家华罗庚著作文章)]https://baike.baidu.com/item/%E7%BB%9F%E7%AD%B9%E6%96%B9%E6%B3%95/14212463?fr=aladdin
统筹方法的核心是:根据工序主次和相互依存关系安排步骤顺序,优化任务进程。泡茶只是一件生活中的小事,但“安排泡茶工序”恰恰简单明了地体现统筹方法的底层思维——即根据工作中各个步骤的特性,对步骤的顺序进行巧妙安排,进而借助自然规律节省时间的思维。在泡茶这件事上,之所以先烧水再洗茶壶,是因为“水在煤气灶上烧”不会在时间和空间上对“洗茶壶茶杯”这道工序造成任何干扰。这里的时间和空间因素即统筹方法考量的自然规律因素。
因此,我对于“统筹方法”的理解更为宏观。工序的依存关系只是众多客观规律中的一种,在日常生活中可能有别的许多客观规律可供利用。当我们借助这些规律,在这种规律的安排下设计任务步骤,可以节省大量时间并减少重复步骤。见下文示例一和示例二。
更进一步,统筹方法也可以是完全摒弃传统想法,独辟蹊径想出另一条可行的思路和方向,用更加优化的方法达到与既有方法同样的结果,而前者可以节省相当多的时间和精力。见下文示例三。
本科阶段的法学生可以体验各种各样的实习工作,其中有很多与我们现有知识水平相匹配的脑力劳动,如联系客户、法律检索、制作研究报告等;但我相信大部分人的实习任务中均可能含有不同比例的重复性劳动,例如装订卷宗、整理案件材料、信息录入、各类材料中特定数据的统计、固定模板的案件材料起草等。后者的学习价值可能比前者要小很多,因此重复性劳动很大概率会遭到实习生的唾弃和埋怨。但毕竟,既然明知自己资历尚浅,肯定不好推辞这样的体力活,就只能把埋怨藏在心里,期待着第二天能够被安排更有挑战性的任务。
而在我看来,很多重复性工作并不必然意味着“不动脑子”,相反,我经常能感受到重复性工作在具体落实过程中巨大的可优化空间,统筹方法的思想在这些领域中具有惊人的潜力。
以知识产权领域侵权纠纷为例,许多案件的侵权事实和权利义务关系非常明确和单一,且对于同类作品、类似侵权情形的案件,往往可以套用相同的法律文书模板,只要代换原被告信息以及特定的案件信息即可。很多人鄙夷这种工作,认为其终将被计算机程序所代替,但很遗憾,在落实这些案件证据材料准备要求的前提下,你会发现大量无法“脚本化”的个性化步骤,在实际的实践中,计算机程序一键成批地生成案件材料的梦想,在可预见的未来还无法实现。
当然,这里排除了实习单位或实习生使用专业技术公司提供的个性化服务的可能性,之所以不讨论这种情况,是因为实习单位既然应聘你从事重复性工作,即意味着他们不愿耗费成本在生产力工具的升级之上(更加实际的考虑是定制化程度越高的解决方案往往普遍适用性越差,例如知产领域无法适用其他刑事案件、行政案件的工作等);而大部分实习生并没有足够的技术实力和时间精力自行学习编写计算机程序。
我们首先讨论模板化的法律文书准备。当事人的同系列作品可能会被许多不同主体侵权,这时需要对每个侵权主体进行民事诉讼,每一个案件的侵权事实大致相同,唯一不同的是被告信息、侵权作品数量、侵权平台和时间等信息。最传统的方法是事先设置一个模板,然后对不同案件个性化的部分挖空并逐一填写。三两个案子这样处理没有任何问题,但如果涉及的案件数量是50个、100个呢?这时,运用同样的方法,你就陷入到不停打开和关闭word文档,不停复制、黏贴的机械化劳动的深渊中无法自拔、怀疑人生,脑中不经回想起马克思在《1844经济学哲学手稿》中的劳动异化理论。
按照传统的准备案件材料的工序,即按照案件顺序一个一个准备,可能是先制作①事务所函→②委托授权书、然后再准备③证据材料→根据材料制作④证据清单,如果逐个案件依次准备上述材料,原来的50个、100个案子就突然需要200个、400个工序,这个时候你想死的心都有了。但这时,华罗庚的谆谆教诲在耳边回响时,我们不禁灵光乍现——既然每一种类型的案件材料只需要修改特定的部分,那么为什么不转变思路,按照材料类型的顺序准备呢?例如,一口气完成50个案件的起诉状,这时我们又需要祭出一些计算机技术手段,例如利用Office软件搭载的VBA语言,将所有案件的特定数据汇总至Excel表格,然后使用一些命令,将这些数据自动导入到既有的案件材料模板中,实现批量生成同一类案件材料,岂不美哉?
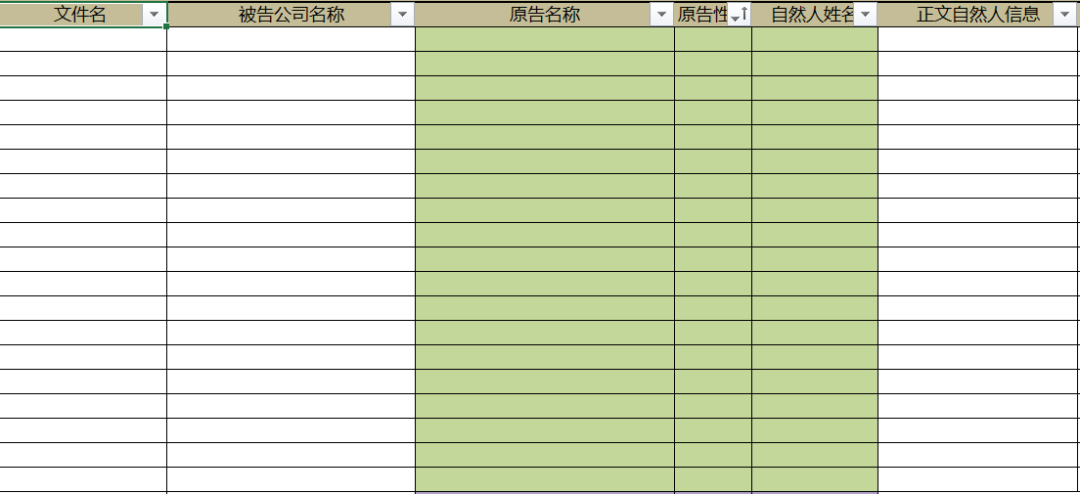
程序的原理很简单,在各个法律文书模板中需要替换的元素以“|XXX|”表示,例如起诉状的原告处填写为“|原告名称|”,随后程序自动搜索模板文件中“原告名称”这一关键词,而后自动将竖线中的内容替换成Excel表格中各个案件对应的特定值。以此类推,样图中|被告公司名称|、|原告名称|、|自然人名称|等内容一键便可替换到模板,自动形成一个个案件的某一类文书。

|
因此,在这一个示例中,原来的传统任务工序是:
【传统工序】=检阅案件1材料→将材料中的特定值导入文书A模板→文书B模板→文书C模板……→检阅案件2材料→导入文书A模板→(循环)……
而优化后的工序为:
【优化工序】=检阅案件1,2,3…n材料并汇总成表格→批量生成案件1,2,3…n的文书A→文书B→文书C…
|
这一工序的变化节省下来的时间量是极为惊人的。根据我的实践经验,利用传统方法完成40个案件可能需要1个多月,而基于优化后的方法,只需要一个礼拜不到。当然,有人会质疑,时间的节省并不是工序的变化带来的,而是因为计算机程序的作用。这个方法的改进确实需要一定的知识,但思路的转变更为重要,没有思路的拓宽,我是根本想不到利用计算机程序的。况且,在我尚未开发出这一套程序之前,我就已经更改了案件准备工作中的顺序,实现了从案件顺序到文书顺序的转变,就这样一个变化也可以节省大量时间,因为将重复性动作聚集到一起也会有熟能生巧,提升速度和准确度的效果。
【示例B:同类案件证据材料准备】
另外一个重头戏是证据材料的准备,这对我来说是个很大的问题,因为这些操作不同于法律文书的准备,前者无法再依赖既有Office软件的宏语言,而是充斥着大量“需要人工操作”的步骤。正因为此,我在准备一个案件的完整材料过程中,法律文书和证据材料的耗时比达到了惊人的2:8。为什么这一道工序会如此繁杂呢?
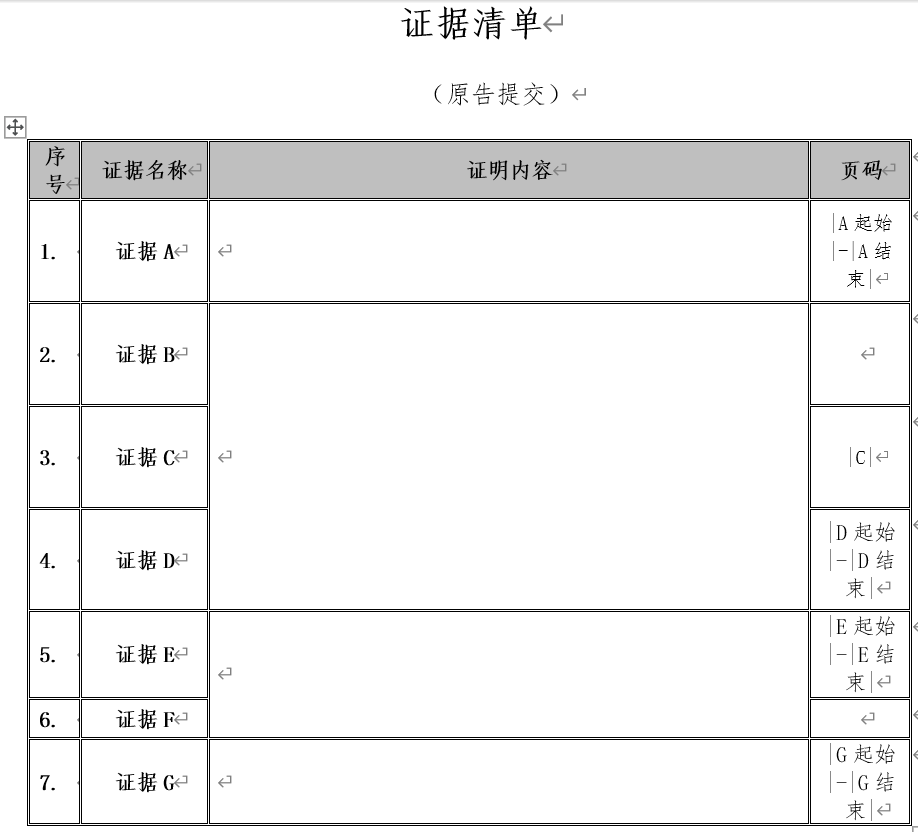
这是因为一个即使是非常简单的案件,也通常被法院要求提供诸多种类的证据材料。一个案件的材料可以多达7种,那么准备100个案件的材料岂不是要编辑700次文件并一个一个组合形成证据附件?一个案件几十页附件要标注页码是不是需要一页一页加?附件准备完是不是还要逐个校验每个案件的材料占据了多少页数,才能在清单上标注准确的页码?……
之所以举这个例子,是因为它太典型了——这道工序涉及的具体步骤是难以利用计算机程序抽象成一个可执行脚本一次性完成的,但其本质上又没有任何技术含量,仅仅对速度和准确度有所要求。因此,可以说,即使是顶尖律师,也不得不面临这类重复性劳动的折磨(当然他们会选择将这种折磨转嫁给实习生)。但,既然我们掌握了统筹方法的武器,就能够放下浮躁,忍住摔电脑、砸键盘的冲动,思考如何简化工序。
其实道理是一样的,我们不妨按照证据材料类型顺序而非逐个案件顺序准备。一些材料是当事人业已提供的,一些是需要自己组装和编辑的,我们不讨论具体材料的组装,仅假设每个案件的证据A/B/C/D/E/F/G这7个材料都已经存在,这种情况该如何处理?
这时,手里如果有50个案件,我们已经拥有了350个pdf文件,文件夹的结构如下:【50个案件的文件夹→每个案件的文件夹→A/B/C/D/E/F/G这七个子文件夹,每个子文件夹内放有对应类型的证据文件.pdf】,如何组成一个个证据附件呢?
传统方法是前往每个案件的每个材料的文件夹,按照证据清单顺序逐个打开和组合。例如:打开案件1文件夹→打开证据类型A文件夹→打开A.pdf文件→打开B文件夹→打开B.pdf文件,与前一个文件组合→打开C文件夹→……这样实在是太复杂了。
面对这种情况,我相信很多人已经开始幻想某种魔力的存在,让每个案件的每个材料自动汇合在一起,怪怪按照顺序排队,再自动保存,简直完美!——那你就想吧哈哈哈哈。
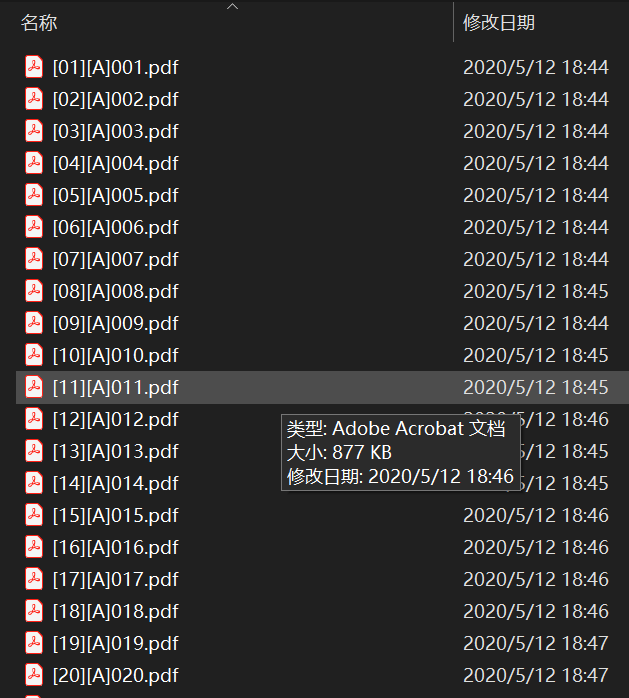
我们还记得证据材料的文件结构其实是很清晰的,怎样筛选出所有这些pdf文件并让他们按照案件顺序1-2-3和材料顺序A-B-C排列和组合呢?我的操作方法是将案件材料批量重命名(文件或文件夹的批量重命名工具在网上随处可得,这些工具都有非常精巧的批量命名规则)。将文件名的结构设置为“[案件序号#1-50][材料类型序号#A-G][案件序号].pdf”。这时,我们回到前一级目录使用Windows搜索50个案件文件夹内的“.pdf”——,所有的pdf文件就会显示在结果中,但这个时候次序还是乱的。但有了刚才文件重命名的基础,这时我们只要将搜索结果按照文件名顺序排列,就会得到如下结果:
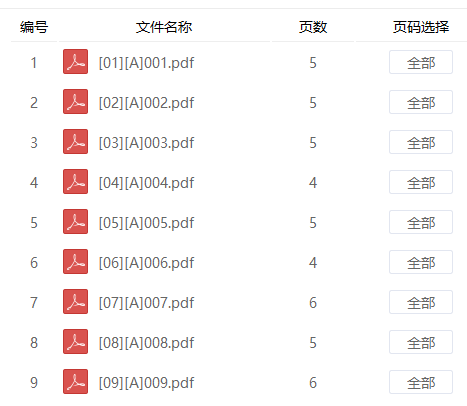
[001]证据清单[01][A]001[01][B]001[01][C]001……[02][A]002[02][B]002[02][C]002……
这样,因为文件头的序号,同一个案件的材料会按照[XX]顺序排列在一起,按照案件序号顺序排列;而在一个案件的内部,不同类型的材料又会按照A-G的顺序排列,这样,只要全选,就可以使用Adobe Acrobat将数量极为庞大的pdf文件按搜索结果的顺序组合成一个pdf文件,文件庞大,但是好在页码是完全按照期望的顺序排列的。
这个时候,如何将这个组合版材料拆分成一个个案件的材料呢?我们可以使用PDFsam这一软件进行pdf拆分操作,其拆分的逻辑有很多种。这里我们用“每'n'页分割”比较妥当,因为每个案件的材料页数是不定的,有的是15页,有的或许只有12页,因此只能用第二种穷举法的规则。
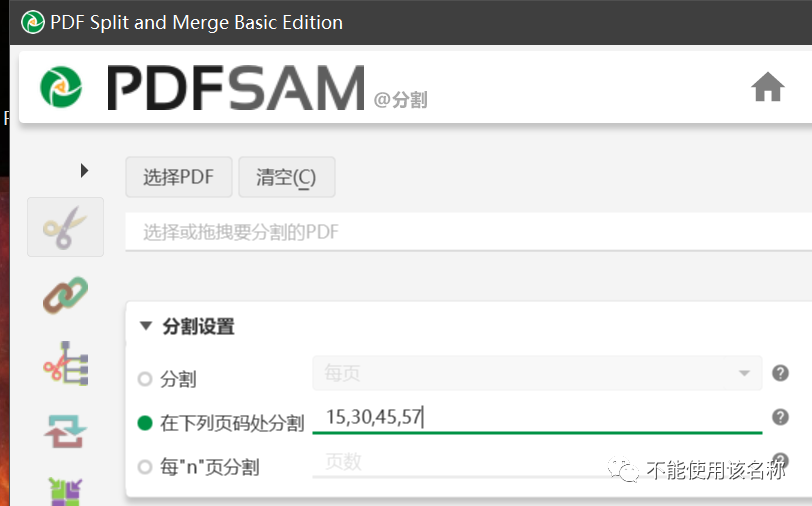
我们可以自由设置在第x1,x2,…xn页之后分割成第二个pdf,规则则取决于我们输入的数字15,30,45,57……按照样图中的设置,一个100页的pdf就会分割成1-15页、16-30页、31-45页、46-57页、58-100页这五个pdf文件。如何判定每个案件材料占用多少页呢?这又是一个疑难问题,我们总不见得打开那个组合版pdf文件逐个案件计算吧?这太麻烦了。
这时,我们暂且先放下材料分割的任务,因为页码信息不掌握,就无法设置分割材料的页码依据。而页码信息却跟另一道工序息息相关,即证据清单中的页码信息。例如案件1的材料A有5页,在对应证据清单内必须标注这个材料的页码为1-5,以此类推。
我首先想到的办法是按照类型的将每个案件的材料导入到迅捷pdf转换器,其会自动读取并显示每个pdf文件的页数,这样就能直接复制黏贴数字了。
这样,利用之前制作法律文书的Excel表格,我们可以手动录入这些材料所占用的页数。但毕竟,证据清单要求的材料页码格式是“起始页X-结束页Y”这样一个范围,而非每个材料的页数。因此,考虑到后续我们依然要利用Excel的宏语言将页码信息录入每个案件的清单,不妨利用之前程序的运行规则,激昂证据清单中的页码位置设置成“|起始页X|-|结束页Y|”,然后在Excel表格中增加起始页X、结束页X的列,程序会自动将对应数值代入到"|A起始|-|A结束|"文本。下一步工作就是批量设置表格内的页码数值,我们不需要手动一个个录入,可以利用一系列函数进行自动运算,如自动求和。A起始页码均为1,因为它是每个证据附件的首页,B起始页码均为A结束页码+1,因为材料是按顺序排列的,以此类推。
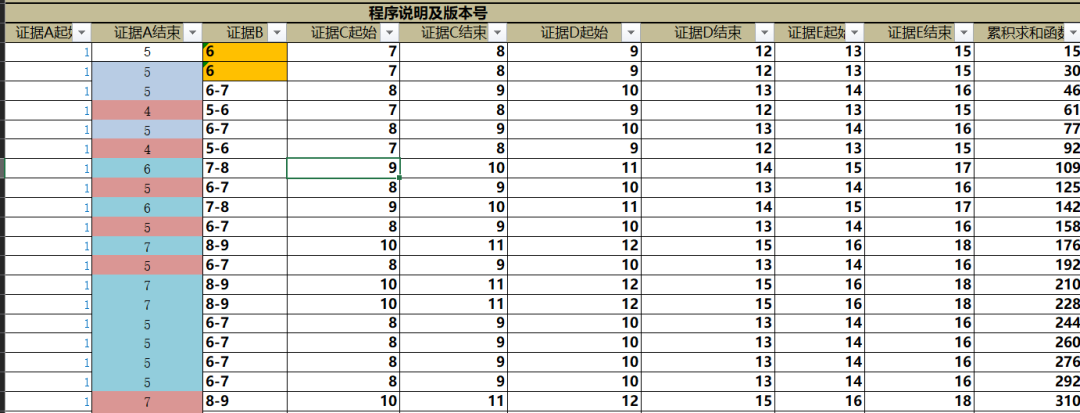
这样,我们完美录入所有案件(细化到每一个材料)的具体页码范围值,最终就能计算出每一个案件证据材料使用的页码数(即为最后一个材料结束页代表的数字),完成这一步之后,后续证据清单的批量生成,就不用再手动填写每个案件的材料页码了。
接下来我们就能继续进行证据材料文件的风格了。但掌握了每个案件材料的页码和数量还不够,因为原先的材料是全部累积起来的,我们需要计算的出每个案件的完整材料在那个大杂烩文件中的第几页结束,才能设定程序的分割规则。因此我们需要累积求和。累积求和函数如下:
=SUM(OFFSET($最后一个证据结束页码所在的列$2,0,0,ROW()-1))
我们在样图的“累积求和函数”这一列中可以看到函数自动运算的结果,即第一个案件至15页结束,第二个案件至第30页结束,第三个案件自46页结束,以此类推……
最终,最后一个案件的累积页码数和刚才组合的案件材料pdf文件的总页码数完全一致,说明我们的方法完美奏效并且非常精准——得到的最后一页页码数为1714,这也是pdf文件的页数。

这时我们不要高兴地太早,刚才PDFSAM分割pdf文件页码分割规则为n1,n2,n3,n4,而现在Excel表格仅仅是竖向排列,怎样让他们连起来并用逗号间隔呢?难道自己用手输入逗号吗? No!我们先用下滑的方式制作出仅含有“,”的一整列,和数值平行,然后利用以下函数结合两列数值为一列的函数:
=CONCAT(逗号所在的列, 累积求和结果所在列)
即可自动结合两列表格中的字符为一列,得到竖向排列的n1,n2,n3,……
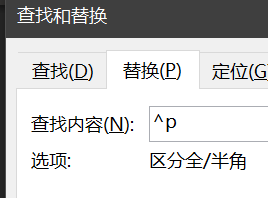
这时我们还面临最后一个问题,Excel表格复制一列黏贴到文本文档或word文档,会保留一个个段落占位符,此时仍为纵向排列,难道这个时候还要一行一行删除回车吗?No——实习生发出了拒绝被剥削的怒吼!我们腰斩都到最后!我们在计算机二级考试里学到过一个替换特殊格式的功能,每一行的回车其实使用了一个段落标记,这种段落标记可以用^p表示,将替换结果设置为空,即可删除所有回车,将原来纵向排列的数据还原成横向排列。
这样,我们大费周折,终于得到了n1,n2,n3,n4……这个数据供PDFSAM程序分割制作好的证据材料组合版文件。
|
综上,在这一示例中,我们可以对比一下优化前后的工序:
【传统工序】=打开案件1材料A→打开材料B和前一文件组合→打开材料C和前一文件组合→……打开案件2材料A→(循环)→打开案件1组合版材料记下材料A的页码→记录到证据清单中→记下材料B页码→记录到证据清单中→……(循环)
而优化后的工序为:
【优化工序】=批量命名所有案件的所有材料,搜索结果顺序排列直接组合成一个pdf文件→使用工具批量检测每个案件的每个材料的页码,结合Excel函数记录每个材料页码的起始页和结束页,并计算出一个案件完成材料的页码数→累积求和,使用前述方法导入PDFSAM软件自动分割完整版pdf文件为一个个案件的材料→使用Excel宏语言自动将材料页码导入到每个案件的证据清单中
|
你别看【优化工序】的阐述性文字反而更多,这是因为在【传统工序】中我用了大量“……”和“(循环)”省略重复性步骤,要是完整呈现,我可以写1万字,这些步骤可以做到你手指发软,恨不得马上在知乎抱怨996,看些入关论调整一下情绪。
上述头脑风暴的过程仅仅耗费了我半个小时不到的时间,却将原来需要4-5小时完成的任务压缩在半小时内便轻松解决,不用摔电脑,也不用换新键盘了。
【示例3:将非常模糊的图片转化成可编辑的word文档?】
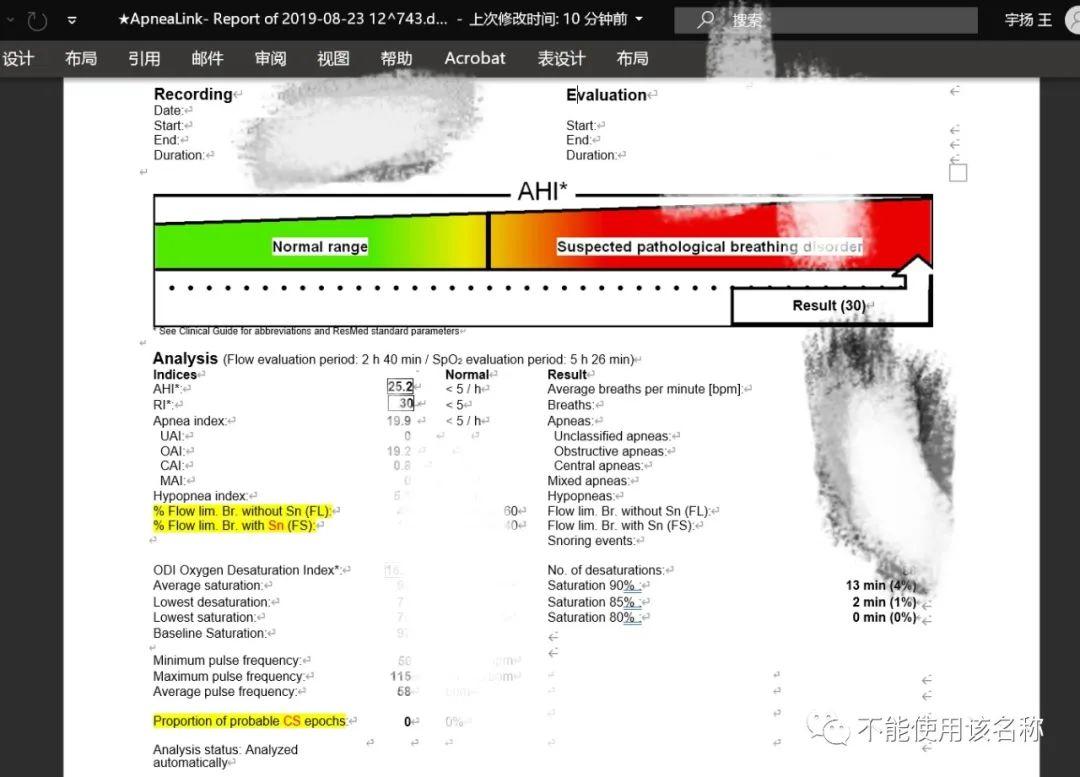
在曾经的实习期间,带教律师给我发了这样一张模糊的图片,要求我转换成格式一模一样的word文档供其翻译和编辑。我曾经收到过身边人不少这样的请求,但显然,提出这样请求的人往往过于高估计算机文字、图像识别的水平和性能——这样一份样图的拍摄角度不正、光线异常、文字轮廓不清晰,如果直接使用相关软件强行转换,最终的结果只会是一堆无法使用的乱码。

有人会问,这种苦差事也有统筹方法的思维吗?当然!这就是我在上文提及过的宏观的统筹方法的思维——用尽你的每一个脑细胞思考:当一条路基本上无法走通的时候,有没有可能替换成别的方法,最终收获一样的结果。
当时我陷入到转换来转换去都是乱码的僵局,非常烦躁。但是,华罗庚的谆谆教诲又在我耳边浮现。我一个激灵,突然想到——这个图片似乎是某个软件生成的数据,这可能是某种仪器的检测结果——那么互联网上是否可能存在这一模板更清晰的图片甚至是源文件呢?我挑选了图片中几个关键词在谷歌内搜索,果然搜索到了这个模板的来源——它是一个便携式健康检测仪器的周期性检测报告。我一步步搜索到这个产品的官网,真的最终搜索到了清晰的样张,完成了文字识别,并且完美保留了这些图形和颜色。带教律师得知了我的方法后,对这种独辟蹊径的思路非常震惊。
结语
上述三个示例是我曾经在实习过程中的心得体会,在此分享仅仅是为了打破现在的人对于重复性劳动的普遍贬低和厌恶。
我非常不同意“重复性劳动就是不动脑子的”这种观点,这种预设立场的自我贬低可能会导致一个人思维僵化,放弃对“剥削”的抵抗。在上文提及的一切金点子能从脑瓜里浮现的一个前提基础,就是那个脑瓜的主人必须尊重重复性劳动的意义,并思考如何将重复劳动巧妙化解。甚至,我认为这种重复性劳动岗位也是具有不可替代性的,因为如果人们都在用传统方法做事情,而你独辟蹊径,可以用5倍乃至10倍的效率完成同样的事情,甚至更加出色且精确,那么,你就很容易将其他人竞争下去。
或许有人会质疑,本文的大部分示例都要求一定的计算机基础知识,并非对所有人普遍适用。但是,我只是借此文强调一种思想的力量,统筹方法是一种思想武器,他可以用来编写计算机程序;可以用来干杂活,也可以用来泡茶;可以用在法律行业,也可以用在其他各行各业的具体事务中——每个事务都有它独特性,解决方案有千千万万种,但不变的, 是一种努力观察事物规律并用以优化流程的思想和精神。
(以下这一段又是我夹杂的私货,可以无视。)
现在很多人借996现象抛出诸如“内卷”、”入关“等概念,认为996起源于同质化竞争,只有掠夺资源才能化解竞争困境。但一件事情究竟是不是同质化竞争,某些时候是由你自己决定的,内卷论和入关论给不了你任何奇思妙想。甚至,这些宏大的陈词滥调根本无法运用到我们工作中的每个事实中——我们在上文提及的案件的准备是程序正义所必须的,人人都希望随便给法院交个复印件就能胜诉,但实际上是不可能的。这种无法避免的程序性事项难道也要怪罪于剥削、996、内卷吗?
相信统筹方法吧,这不是一句模糊的鸡汤,也不是一个收割智商税的亚文化标签,它是一个非常具体的策略——即我们可以思考工作过程中的任何一个细枝末节,有没有可能借助一定规律压缩这些琐事对我们时间精力的消耗。
与其宣扬炸平西半球,不如好好宣传统筹方法的重要性,真正提升社会主义社会生产力水平。
本篇文章来源于本人微信公众号: 不能使用该名称
